

Most AI systems look impressive in a controlled demo but fail when they encounter messy, real-world data. QuantPi provides a unified validation layer - a rigorous "stress test" - to ensure your AI is safe, reliable, and cost-effective before you ship it to customers.
.jpg)
Traditional ways of testing AI are no longer sufficient for professional deployment
QuantPi transforms complex AI evaluation into a flexible system of modular building blocks. By seamlessly assembling these plug-and-play components together, you can instantly configure a test suite tailored to any model, modality, or purpose.
Launch fast by leveraging a rich library of pre-built, ready-to-use testing blocks for immediate time-to-value, while retaining the freedom to endlessly extend the ecosystem with your own custom components. This modular architecture drives end-to-end impact across three core pillars:
The classic rule of "garbage in, garbage out" applies just as much to testing AI as it does to training it. To guarantee meaningful results, the QuantPi platform equips you with the essential tools to evaluate, refine, and elevate the quality of your test data.
Evaluate your test data to map exactly which scenarios it covers, exposing hidden biases and critical gaps before they impact your models.
Raw data often lacks the crucial metadata required to define specific test scenarios. To overcome this limitation at scale, the QuantPi platform enables you to leverage AI tools (e.g. CLIP, LLM, ...) to automatically generate these missing annotations. To account for potential AI annotation errors, the platform then calibrates the annotators on a data subset and adjusts the final test results to guarantee reliable, unbiased outcomes.
Scale small, high-quality data samples into thousands of simulated "what-if" scenarios—such as weather variations, degraded inputs, and edge cases. This proactive stress-testing eliminates operational blind spots and prevents unexpected failures after deployment.
Because high-quality, representative data is often rare and expensive to collect, the platform leverages uncertainty quantification via confidence intervals to maximize testing efficiency. This approach allows you to quickly determine if your existing data is sufficient to prove a system is simply "good enough."


What makes the technology powering the QuantPi platform unique is that it is modality agnostic, you can use it to make sure that the data you use for testing is high quality, regardless if it is text, images, video, audio or multi-modal.
Striking this balance is critical, yet most testing frameworks force you to compromise and only get halfway there:
The right answer to the wrong question: Traditional metrics like cross-entropy or mean squared error offer mathematical precision but fail to capture real-world AI behavior. Relying on these generic checklist metrics gives you a perfectly accurate measure of the wrong thing.
The wrong answer to the right question: To test complex expectations, many teams now use an "LLM-as-a-Judge." While this targets the right business questions, AI judges are prone to hallucinations and errors, leaving you with biased test results and unexpected failures in production.
With the QuantPi platform, you can get the best of both worlds:
QuantPi offers a vast library of pre-built metrics for classification, object detection, and generative models. Crucially, these metrics feature built-in risk modeling, allowing you to translate technical data directly into quantified business impacts and probability-based risk estimations.
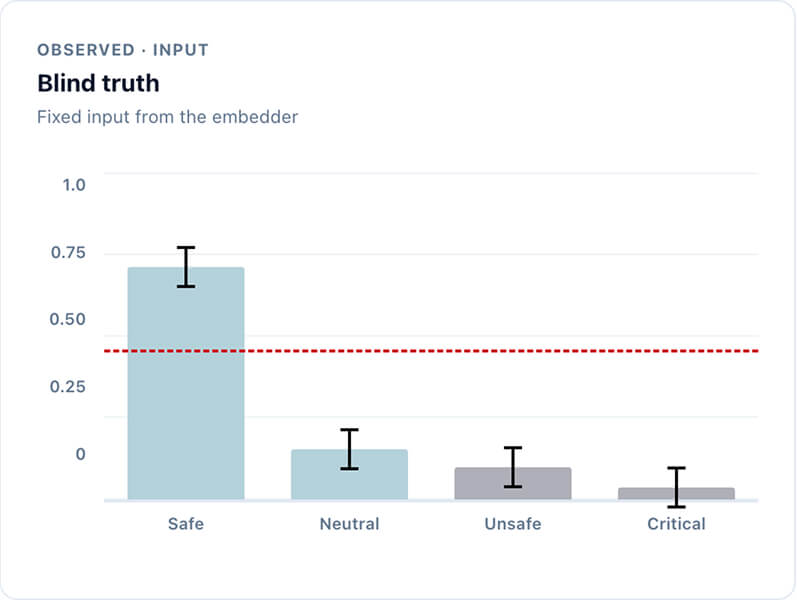
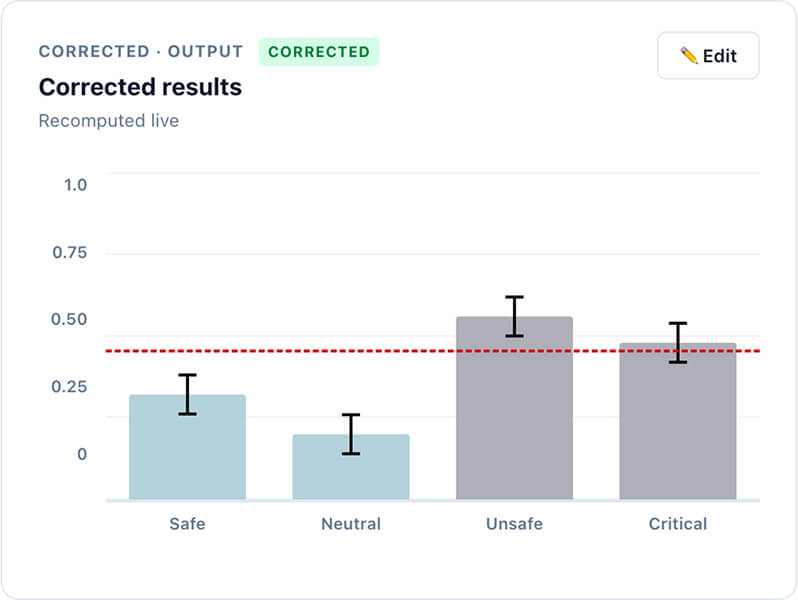
Expecting a flawless AI judge is unrealistic. QuantPi lets you easily calibrate your AI-judge by benchmarking it against a small golden dataset just once. The platform then factors the judge's error rate into your final calculations—transforming unpredictable AI hallucinations into standard, manageable measurement errors. This ensures your test results remain reliable and perfectly aligned with your actual standards.
Global averages hide critical flaws. QuantPi breaks down model performance into granular categories—like fairness, safety, and operational robustness—to expose exactly where your system succeeds or struggles. By isolating these specific vulnerabilities, you can accurately forecast real-world risk and give your development team a precise, data-driven roadmap for debugging and building the next version.
AI test results only drive impact when they deliver clear, actionable insights. When decision-makers, engineers, and risk officers are overloaded with raw data, they either waste precious time or miss critical findings altogether.
To cut through the noise, the QuantPi platform automatically generates targeted dashboards tailored to every stakeholder in the AI lifecycle, ensuring your testing efforts drive actual decisions:
Highlight exactly where a model excels and where it fails, giving developers a crystal-clear performance roadmap and actionable recommendations to optimize the next iteration.
Automatically generate audit-ready documentation that guarantees the full traceability, reproducibility, and defensibility of your AI test results.
Enable product owners and business leaders to compare multiple models at a glance, tracking progress over time to confidently select the best candidate for production.
Deliver standardized, intuitive summaries of model behavior, safety boundaries, and limitations to streamline transparent and trustworthy communication for both internal alignment and external stakeholders.
QuantPi's MCP integration means validation isn't a separate step requiring specialized, PhD-level data scientists anymore - it's a function call. Connect QuantPi to your existing agentic workflows, GRC tools, CI/CD pipelines and reporting systems. Fully flexible and easy to use. Any input. Any output format. You control it via your agentic layer, while QuantPi does the heavy lifting of generating reliable results and proof at scale

It acts as a final validation step in your normal build-and-release process.
The platform runs where your data lives—whether in a public cloud, a private cloud, or a fully "air-gapped" environment.
It allows different teams to use one company-wide quality standard, ensuring identical, standardized risk reports across the entire organization.
Use the MCP server (or the API) to call QuantPi directly from your own pipelines and agents. Validation runs as a step in your workflow, and the results come straight back to the tools your team and agents already use.
Public cloud, a private cloud you control, or a fully air-gapped network with no outside connection.
Sign-in through your SSO, permissions by role, a separate workspace per team.
Self-host or run air-gapped and nothing crosses your perimeter, not your models, not your data.


%201.svg)

.jpg)